How Large Language Models Actually Work (No Math Required)
Large Language Models or LLMs are the technology behind ChatGPT, Claude, Gemini, and virtually every impressive AI tool you have encountered in the past few years. They can write essays, answer questions, summarize documents, generate code, and hold nuanced conversations. But how do they actually work? Not the mathematics the intuition. The mental model that helps you understand what is really happening when you type a message and get back a remarkably coherent response.
The Core Idea: Predicting the Next Word
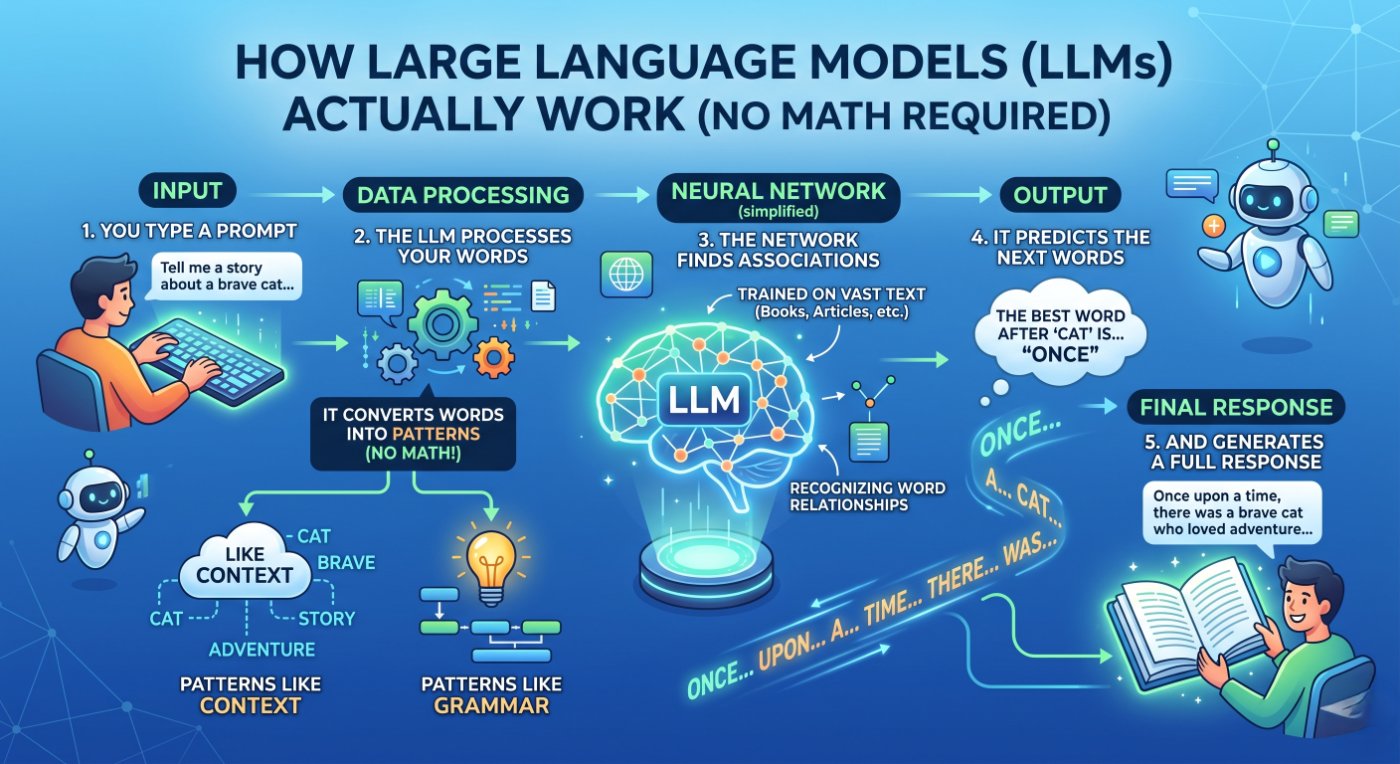
At its heart, an LLM does one thing: it predicts what word (or more precisely, what "token") should come next in a sequence. That is it. Everything the essays, the code, the explanations, the jokes emerges from this one surprisingly powerful operation performed billions of times.
Imagine you are playing a word prediction game. I write: "The capital of France is ." You confidently say "Paris." How? Because you have read countless sentences in your life that associate France, capital, and Paris. You have absorbed patterns. An LLM does exactly the same thing but instead of absorbing a few thousand books, it has processed hundreds of billions of words from across the internet, books, scientific papers, and code repositories.
Training: How the Model Learns
The training process works like this: the model is given enormous amounts of text data. It makes a prediction about the next word. It checks whether it was right. If wrong, it adjusts its internal settings (called "weights" or "parameters") very slightly to do better next time. This process is repeated trillions of times across the entire training dataset. After enough iterations, the model has developed an incredibly rich internal representation of language, facts, logic, and even common sense.
GPT-3 had 175 billion parameters. GPT-4 is estimated to have over a trillion. More parameters generally means more capacity to represent complex patterns which is why bigger models tend to be smarter, though size alone is not everything.
The Transformer: The Architecture That Changed Everything
The key innovation that made modern LLMs possible is the Transformer architecture, introduced by Google in 2017. The critical mechanism it introduced is called "attention" specifically, "self-attention." This allows the model to look at every word in a sentence and determine which other words are most relevant to understanding it. In "The bank refused the loan because it was already overextended," attention helps the model understand that "it" refers to "bank," not "loan." This context-sensitivity is why modern LLMs feel so much more coherent than older systems.
Why Do LLMs Sometimes Get Things Wrong?
LLMs can produce confident, fluent, completely false statements a phenomenon called "hallucination." This happens because the model is optimized to produce plausible-sounding text, not factually verified truth. It has no access to verified databases, no ability to check its own outputs, and no concept of "I don't know" unless specifically trained for it. This is a fundamental limitation that engineers are working hard to address but it means you should always verify important claims from any LLM.
"An LLM is not a database of facts. It is a model of language extraordinarily good at generating plausible text, which is both its power and its danger."
What Makes One LLM Better Than Another?
Several factors determine LLM quality: the size and quality of training data, the scale of the model (number of parameters), the quality of the training process, and critically the fine-tuning and safety work done after initial training. RLHF (Reinforcement Learning from Human Feedback) is a technique that uses human raters to teach models to give better, safer, more helpful responses. This is why Claude, ChatGPT, and Gemini feel different from each other even though they are built on similar underlying technology.